How Do Self-Attention Masks Work?
As I’ve been working with self-attention, I’ve found that there’s a lot of information on how the function works, but not a lot online that explains why and how a mask works. Additionally, I had several questions revolving around the masks. For example:
- Why is an attention mask applied to multiple layers?
- Why aren’t attention masks applied along both keys and queries?
- Do the key, query, and value weights mix up the sequence order of the original matrix?
I decided to figure this out by writing out the matrices. Now, I think I have a much better understanding of how masks work. I also learned that I didn’t exactly know how a linear layer works across 2-dimensions which would’ve cleared up the last point I listed above.
I want to share my process of working through how attention works. Maybe it can help those who have the same confusion as I did.
This article will use very few numbers as I feel it distracts from the meaning of what exactly attention is doing. Doing a bunch of matrix multiplications with numbers just results in more numbers and is hard to visualize when looking at the bigger picture. Rather, I am going to use a lot of variables.
Problem Setup
Let’s start with a single matrix X with 4 words. When these words are transformed into their token embeddings, each token will have an embedding size of 3 values. Below is what our sentence will be:
“a b c D”
What a nice sentence! Now let’s turn those words into tokens.

Our sequence is essentially made of 4 tokens. Each token is a vector of 3 values. Now let’s turn these tokens into a matrix, X.

This is the matrix we want to transform using self-attention.
Preparing For Attention
To prepare for attention, we must first generate the keys, queries, and values using weighted matrices. For this sentence, we want to transform it into a 4✕2 matrix. So, each of the weight matrices will be of shape 3✕2. For example, below is the weight matrix for Q named QW.

Using the QW matrix, we can obtain the query matrix, Q.


Now we have a representation of Q. Notice how each vector in the resulting matrix is not a linear combination of all other tokens. Rather, each vector is a linear combination of itself and some weights. The first vector is just a linear combination of a. The second is just a linear combination of b. This transformation does not mess up the sequence order within the matrix. a is still at the top of the matrix and D is still at the bottom of the matrix. For future operations, I am going to denote the entries of Q using the rightmost matrices to easily visualize the vectors of a, b, c, and D and how these vectors haven’t been transformed into some combination of each other.
This transformation is the same for the keys and values resulting in the following matrices.
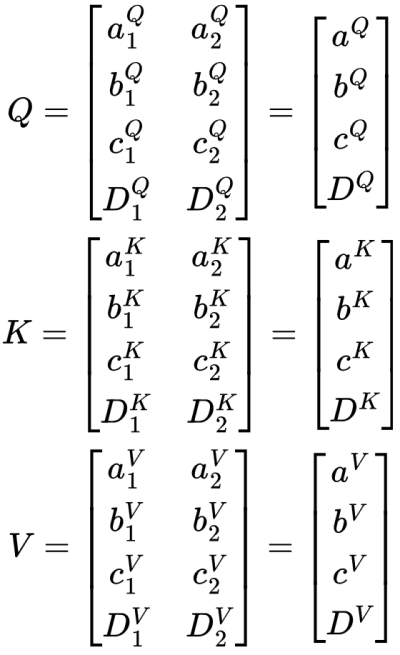
Our setup is complete. Now to compute the attention of this sequence.
The QKᵀ Matrix
Attention is defined by the following formula.

To make it easier to visualize what’s going on, I’m going to remove the dₖ constant. The Attention is All You Need authors state that the scalar dₖ is used because “We suspect that for large values of dₖ, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.” dₖ is just a scalar helping the gradients, which we don’t care about in this article. So, I will use the following formula instead.
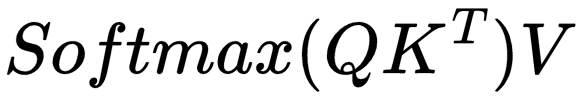
With a mask, the equation is a little different which I will explain in a proceeding section.
The QKᵀ matrix is computed as follows.
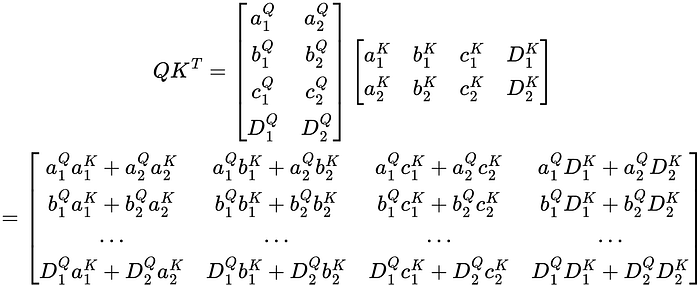
This matrix is very confusing to look at in its current form. So, I’m going to reduce it to its vector product representation. I’m also going to label the rows and columns to help visualize what the matrix represents.
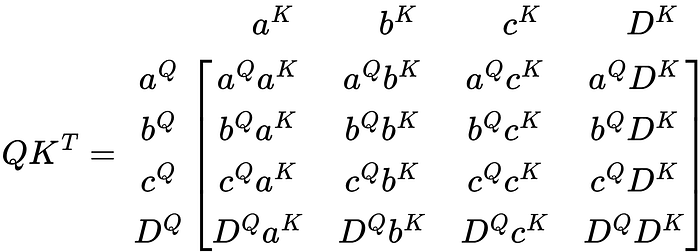
Much better. Each value is basically multiplied by the other including itself in the matrix. This value indicates how much weight each component in V will receive as seen when applying V to this matrix.
Attention Without a Mask
Before going over how masked attention, let’s see how attention works without a mask.
The next step in computing the attention of a sequence is the application of the softmax function to the QKᵀ matrix. Though a question arises, on what dimension should the softmax be applied? In the case of attention, the softmax function is applied over each row.
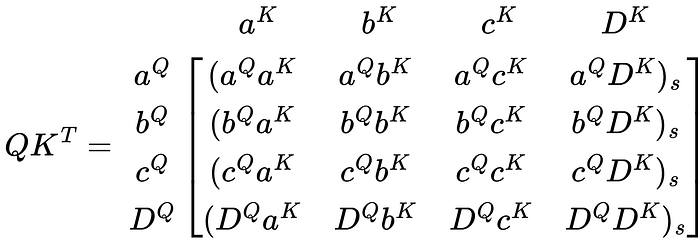
In the current case without a mask, the softmax function is just a normalization function. To reduce clutter, I’m not going to represent it in this matrix.
Now for the final step, multiplying the QKᵀ matrix by the value matrix.
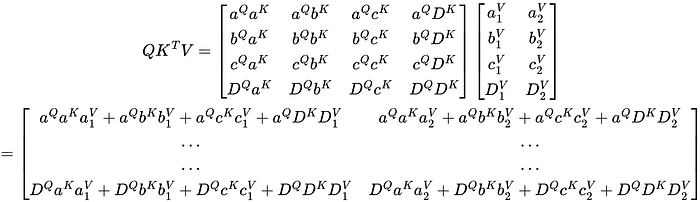
Notice how each encoding in the matrix is a linear combination of the values and the weights in the QKᵀ matrix. Essentially, each row in the resulting matrix is a linear combination of the corresponding row in the QKᵀ matrix and the corresponding column in the value matrix.
The output of the attention module without a mask has each token attend to all other tokens. This means that all tokens have an effect on all other tokens.
The resulting matrix can be reformatted like the following:
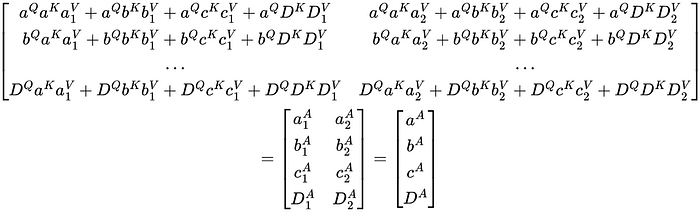
The attention transformation essentially produces a new set of vectors, one for each word in the sequence.
Attention With a Padding Mask
Before calculating attention with a padding mask, we need to add the mask, M, to the equation:
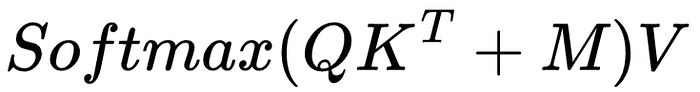
We already have QKᵀ and V, but what does M look like? Remember our sequence is
“a b c D”
What if we replace those arbitrary values with an example:
“I like coffee <PAD>”
Notice there is a pad token. This token may appear because we want to batch a lot of sentences together. The only problem is sentences have varying lengths and matrices are not made to handle varying sizes. To fix this, we can add <PAD> tokens to the sentences to make all sentences the same length.
One problem with <PAD> tokens is that the <PAD> tokens become the most frequent part of a sentence. The model will probably pick up on this and learn that many <PAD> tokens are fundamental to a sentence. Good job model.
To keep the model from modeling the <PAD> tokens, we can mask the positions in the QKᵀ matrix where <PAD> exists in a specific manner. As the example above shows, D is a <PAD> token and we want to mask it. To do so, we will use a mask with the same dimensions as QKᵀ with -∞ along the columns that represent the token we want to mask. The mask will look like the following:
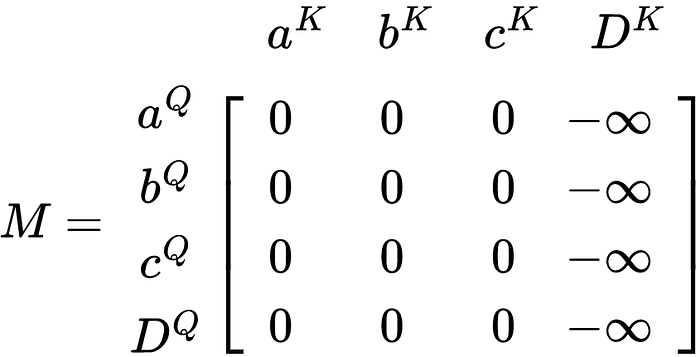
Notice how the column Dᴷ is masked, but the row DQ is not(Apparently Q superscript is not a Unicode character so I will use DQ as a placeholder). The reason for the mask position will come when the matrix QKᵀ is multiplied by V. The next step is to add M to QKᵀ
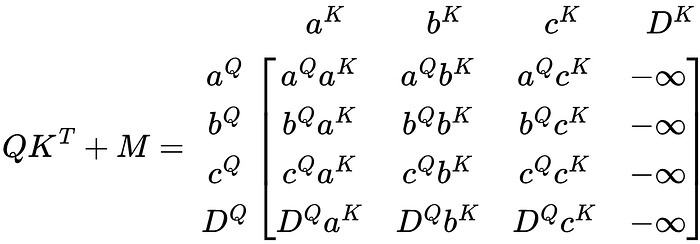
Anything added to -∞ becomes -∞, so the resulting column Dᴷ is a column of -∞. Now, what happens when softmax is applied to the matrix?
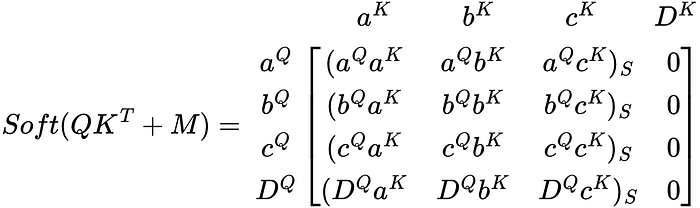
Dᴷ is now all 0s and essentially doesn’t affect the weights of the other values in the weight matrix. Notice how D is not a part of any of the other rows, only in its own DQ row. Like in the previous section, I am not going to worry about the softmax values of the non-∞ values as the function just acts as normalization. Finally, let’s see how the resulting matrix looks when multiplying the weight matrix by the V matrix.
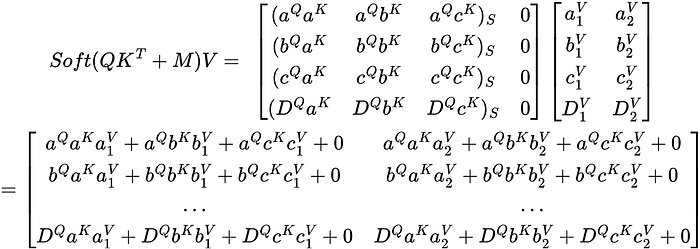
Let’s look at the final matrix a little closer.
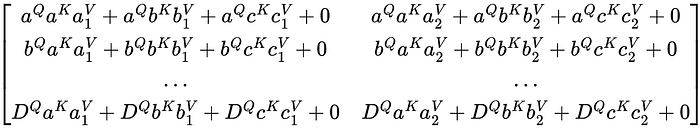
Notice how each row in the resulting matrix does not have the Dᴷ component. So, the D component has no effect at all on any of the other components meaning that any of the padded masked components have no effect on the rest of the parts of the sequence. This is why a padding mask is used, we don’t want it to affect any of the other tokens in the sequence.
What about DQ, it still exists and isn’t masked out. If DQ was masked, then the DQ vector in the matrix would result in a vector of uniform values after applying the softmax transformation. This means DQ will lose all information it previously had. The goal of masking isn’t to completely remove all information of the D token, rather it is to have it not affect any other token. In the resulting matrix, we still want information about D so the model knows there’s a <PAD> token there. We just don’t want the <PAD> token to cause relationships between the components of the other tokens.
Say we masked out both DQ and Dᴷ, then the resulting matrix would look like the following:
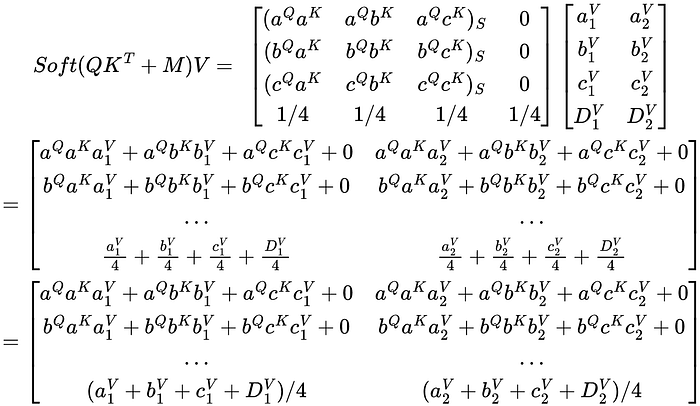
Since DQ and Dᴷ are constants, they don’t add much to the result. The resulting vector in the last part of the matrix is just a combination of V’s components weighted by 1/4. This isn’t a very useful representation of anything and kind of causes D to lose all information of itself, meaning the new representation of D in the resulting vector will be a terrible representation of D.
Attention With A Look-ahead Mask
The look-ahead mask was originally used in the Attention is All You Need paper for the original transformer. The look-ahead mask is used so that the model can be trained on an entire sequence of text at once as opposed to training the model one word at a time. The original transformer model is what’s called an autoregressive model. This means it predicts using only data from the past. The original transformer was made for translation, so this type of model makes sense. When predicting the translated sentence, the model will predict words one at a time. Say I had a sentence:
“How are you”
The model would translate the sentence to Spanish one word at a time:
Prediction 1: Given “”, the model predicts the next word is “cómo”
Prediction 2: Given “cómo”, the model predicts the next word is “estás”
Prediction 3: Given “cómo estás” the model predicts the next word is “<END>” signifying the end of the sequence
What if we wanted the model to learn this translation? Then we could feed it one word at a time, resulting in three predictions from the model. This process is very slow as it requires S (the sequence length) inferences from the model to get a single sentence translation prediction from the model. Instead, we feed it the whole sentence “cómo estás <END> …” and use a clever masking trick so the model cannot look ahead at future tokens, only past tokens. This way it requires a single inference step to get an entire sentence translation from the model.
The formula for self-attention with a look-ahead mask is the same as the padding mask. The only change has to do with the mask itself.
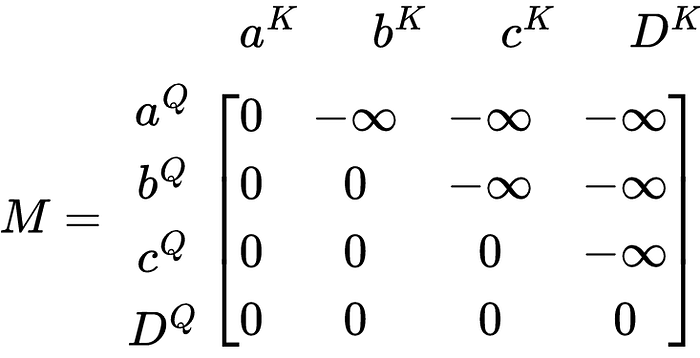
The mask has a triangle of -∞ in the upper right and 0s elsewhere. Let’s see how this affects the softmax of the weight matrix.
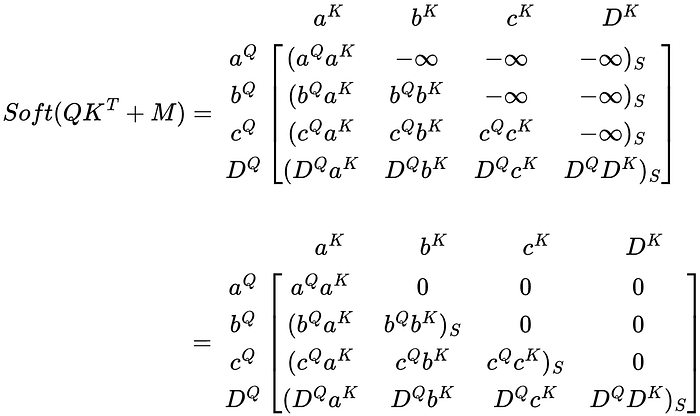
The weight matrix has some interesting results. The first-row aQ is only weighted by itself aᴷ. Since a is the first token in the sequence, it should not be affected by any other token in the sequence as none of the other tokens exist yet.
On the second row, b is affected by both a and b. Since b is the second token, it should only be affected by the first token, a.
In the last row, the last token in the sequence, D, is affected by all other tokens as the last token in the sequence should have context of all other tokens in the sequence.
Finally, let’s see how the mask affects the output of the attention function.
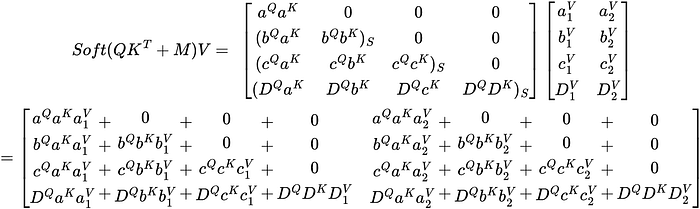
Similar to the weight matrix, the resulting vectors are only affected by the tokens preceding the token represented in that vector. The new token embedding of a is in the first row of the resulting vector. Since this token only has context of itself, it will only be a combination of itself.
The second token b has context of a, so the resulting vector is a combination of a and b.
The last token D has context of all other tokens, so the resulting vector is a combination of all other tokens.
Resulting Matrices
To easily visualize how the resulting matrices are different, I am going to put them bottom-to-top here

Using a Mask For Multiple Layers
One final note I want to make is why a mask is used in multiple layers. It wasn’t immediately obvious to me until I took a closer look at the matrices.
The attention function can be summed up as a single transformation from matrix X to matrix A.
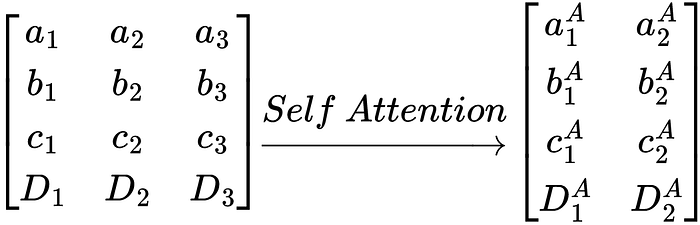
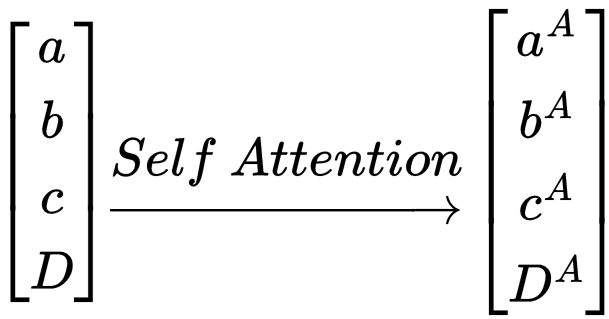
As previously stated, the self-attention transformation retains the context of each of the vectors. The output sequence is just a transformed form of the input sequence.
Say we wanted to mask all <PAD> tokens and say D is a <PAD> token like used in the example above. Then the output Dᴬ is still a <PAD> token, just represented as a transformed embedding. So, any proceeding self-attention function will require a mask to ensure the <PAD> token does not affect any other tokens.
You can imagine a transformer as a sequence of self-attention functions. The linear layers and norm layers don’t mess up the sequence relationship among the tokens, so they are negligible in this example.

Each self-attention function will require the use of the same mask due to the retention of the sequence between self-attention layers. In the example of the padding mask, if the mask was only used on the first self-attention layer, then the sequence will not be affected by the <PAD> token in the first self-attention layer. In all other layers, the sequence will be affected by the <PAD> token because the mask is missing.
Conclusion
The attention mask is essentially a way to stop the model from looking at the information we don’t want it to look at. It’s not a very complicated method of doing so, but it’s very effective. I hope this article gave you a better understanding of how masking works in the self-attention function. Hopefully, I was able to get all the matrix multiplication correct.
If you are interested in learning more about the attention mechanism in general, the following article does an amazing job explaining how it works in detail: http://jalammar.github.io/illustrated-transformer/
